





FAQ - Frequently Asked Questions
Issue:
-
How are RMSEC and RMSECV related to R2Y and Q2Y I see in other software?
Possible Solutions:
-
In some software, the values "R2Y" and "Q2Y" are reported for regression models. The R2Y value is equivalent to the y-block cumulative variance captured (as reported in the 5th column of the variance captured table or the .detail.ssq field of a model).
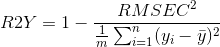
The "Q2Y" value is analogous to R2Y except it is based on the cross-validated results. It is related to the RMSECV values according to this equation :
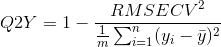
where RMSECV is the root mean square error of cross-validation, m is the number of samples and yi is the actual (aka measured) y-value for sample #i. These relations are only true if the y-block is mean-centered before the model is built.
R2Y and Q2Y represent fractions of variance captured while the cumulative variance captured table and .detail.ssq field represent percentages. They are identical except for a factor of 100 difference between fraction and percentage.
Given a PLS model named "m" which used only mean centering or autoscaling on the y-block, the following code calculates Q2Y:
incl = m.detail.include{1,2};
y = m.detail.data{2}.data(incl,:);
my = length(incl);
Q2Y = (1-(m.rmsecv.^2)*my./sum(mncn(y).^2))
The practical aspects of these statistics are:
- R2Y and Q2Y generally increase towards 1 as a model's fit improves whereas RMSEC and RMSECV decrease to zero
- RMSEC/CV are in units of the original y-block and can be interpreted as "error levels" (They are very similar to standard deviations) whereas R2Y and Q2Y are in fractional units
- It is possible for Q2Y to exceed the 0 -> 1 limit if the predicted y-values are particularly bad.)
Still having problems? Check our documentation Wiki or try writing our helpdesk at helpdesk@eigenvector.com
